常用数据结构
树
二叉树
满二叉树
每个节点都有0个或2个子节点
完全二叉树
除最后一层外,其他层都是满的 最后一层节点从左到右连续排列
完美二叉树
所有叶子节点在同一层,且每个非叶子节点都有两个子节点
二叉搜索树BST
对于任意节点:
- 左子树所有节点值 < 节点值
- 右子树所有节点值 > 节点值
- 左右子树也都是二叉搜索树
AVL树
平衡因子:左右子树高度差绝对值不超过1,==搜索效率最高==
红黑树
节点是红色或黑色
根节点是黑色
叶子节点(NIL)是黑色
红色节点的子节点都是黑色
从任一节点到其所有叶子节点的路径包含相同数量的黑色节点
==口诀:根页黑,不红红==
非二叉树
B树
m阶B树性质:
- 每个节点最多m个子节点
- 非根节点至少有⌈m/2⌉个子节点
- 根节点至少有2个子节点(除非是叶子)
- 所有叶子节点在同一层
- 节点有k个关键字,则有k+1个子节点
B+树
内部节点只存储索引,不存数据
叶子节点存储所有数据,并有指针连接
查询效率更稳定
范围查询效率高
==应用:MySQL的索引结构==
跳表
最高层索引开始,向右查找,如果下一个节点值大于目标值,则下降一层继续查找。这个过程类似于在有序数组中进行二分查找
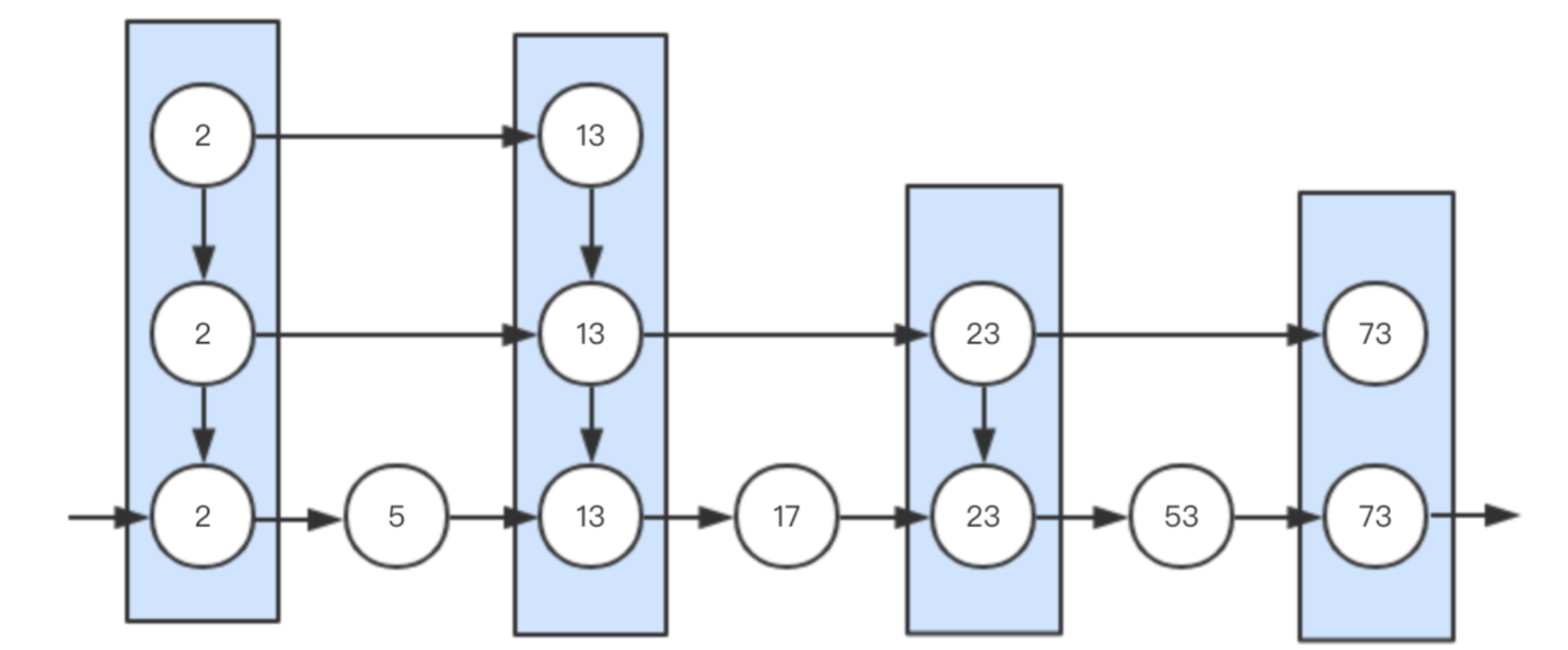
==应用:redis的ZSet==
堆
堆是一种特殊的完全二叉树,一般由数组存储
最大堆:每个节点的值都大于或等于其子节点的值
最小堆:每个节点的值都小于或等于其子节点的值
1 | Queue<Integer> pq = new PriorityQueue<>() |
要去找前3大的数,就构造一个==小顶堆==,先放三个数进来,之后每次进来就判断一下,比堆顶元素小,就丢弃,如果大于堆顶,就移除堆顶,然后入堆,这样下来,就得到最大的三个数
栈
1 | Deque<String> stack = new ArrayDeque<>(); |
队列
1 | Queue<String> queue = new ArrayQueue<>(); |
双端队列
1 | Deque<String> deque = new ArrayDeque<>(); |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 夏天的风吹向哪里!