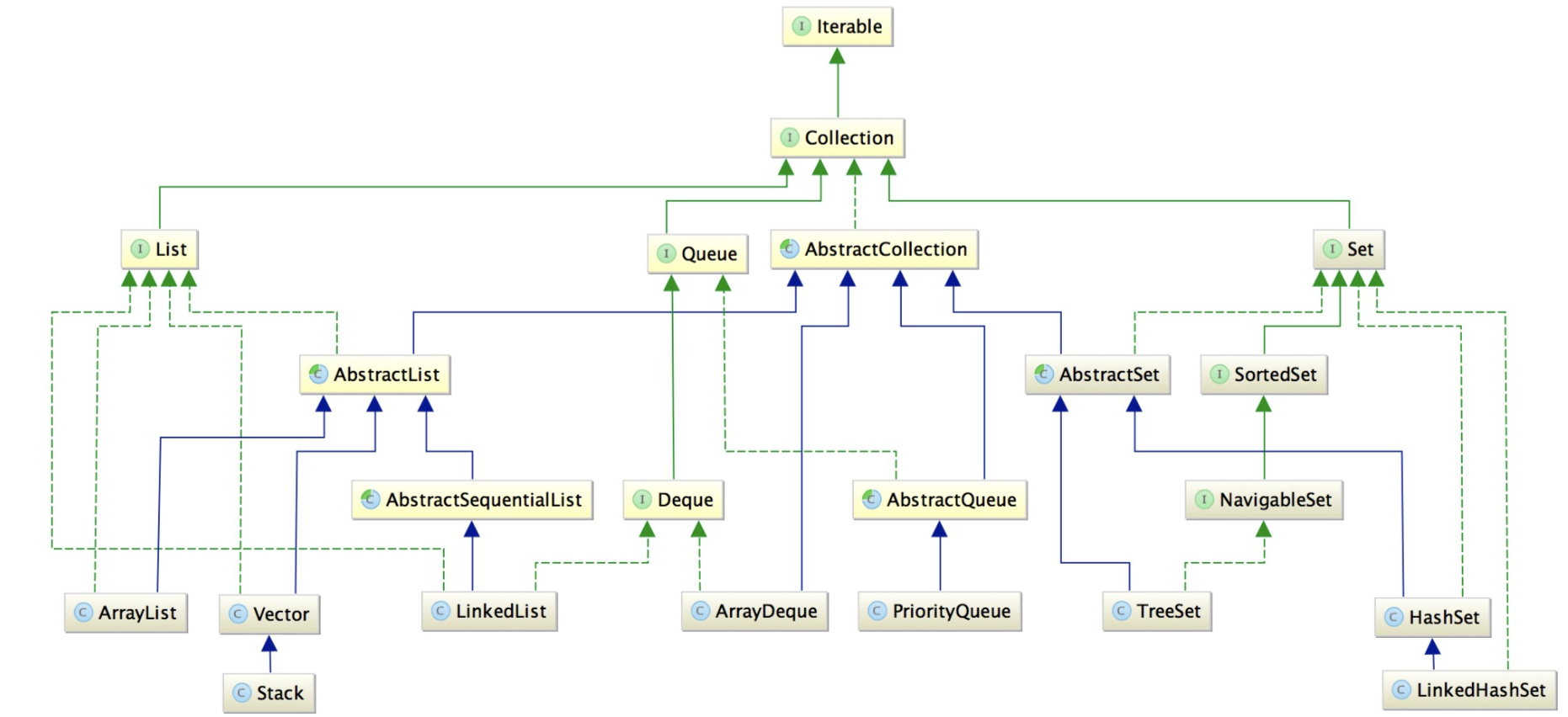
集合
继承关系图
蓝色实线:类继承类
绿色实线:接口继承接口
绿色虚线:类实现接口
List
ArrayList
- 底层结构:普通数组(
Object[]) - 特点:
- 随机访问快(通过下标)
- 增删慢(尤其是中间位置,需移动元素)
- 扩容机制(JDK 1.8+):
- 无参构造:初始为空数组,第一次添加元素时,数量不超过10,扩容至 10,超过10,则添加多少扩容至多少
- 每次扩容为 原容量的 1.5 倍:
newCapacity = oldCapacity + (oldCapacity >> 1) - 扩容通过
Arrays.copyOf()复制原数组到新数组
LinkedList
- 底层结构:双向链表(JDK 1.6 前为循环链表,之后改为非循环)
- 特点:
- 插入、删除两端效率高(只需改指针)
- 随机访问慢(需要遍历查找)
- 实际开发:绝大多数场景
ArrayList更优,因为缓存局部性好且内存连续
CopyOnWriteArrayList
==适合读多写少的场景==
- 底层结构:
volatile transient Object[] array - 核心思想:写时复制(Copy-On-Write)
- 读操作:无锁,直接读;读的时候可能拿到的是旧数组(刚被另一个线程替换),但这不违反并发安全 —— 你读到的是某个时刻的一致性视图;**用
volatile**:写线程修改array引用后,读线程能立刻看到新数组 - 写操作:
- 获取
ReentrantLock独占锁(保证同一时刻只有一个写线程)。 - 复制当前数组(
Arrays.copyOf或System.arraycopy)。 - 在新数组上完成增/删/改。
- 将新数组赋值给
volatile的array引用。 - 释放锁。
- 获取
问题
1. 线程安全性?
- **
ArrayList**:非线程安全 - **
LinkedList**:非线程安全 - **
CopyOnWriteArrayList**:线程安全(通过写时复制 +ReentrantLock实现)
2. CopyOnWriteArrayList 能保证数据绝对一致性吗?
不能。读线程可能读到旧数据,这称为最终一致性
Map
Hash冲突的办法
开放定址法
核心思想:当发生冲突时,寻找下一个空闲的哈希槽

链地址法
再哈希法
核心思想:使用多个哈希函数,冲突时换一个哈希函数
hashcode和equals
为了遵守这个契约,并且让 HashMap(以及 HashSet、Hashtable 等)正常工作,**重写 hashCode() 时务必重写 equals()**,反之亦然
因为是这样查找的↓
当调用 get(key) 时,同样先计算 hashCode() 找到桶位置,然后遍历桶内的所有元素,调用 equals() 逐个比较键,找到相等的键才返回对应的值
HashMap
1.7之前:数组+链表
1.8之后原理:
一、put操作
底层:数组 + 链表 + 红黑树
数组:
Node<K,V>[] table(初始容量 16,负载因子 0.75)链表节点:
Node实现Map.Entry(单向链表)树节点:
判断是否需要树化:插入链表后,若链表长度 ≥
TREEIFY_THRESHOLD - 1(实际为≥8),调用treeifyBin():- 如果数组容量 < 64,则先扩容(而非树化)==扩容原理下面==
- 否则将链表转为红黑树
当树节点数 ≤
UNTREEIFY_THRESHOLD(默认 6)时,红黑树退化为链表。
红黑树的作用:在哈希冲突严重时,将查找/插入/删除的时间复杂度从 O(n) 优化为 O(log n)
二、get操作
- 计算
hash和下标(n-1)&hash - 如果
table[i]不为空:- 检查第一个节点:
hash和equals都匹配 → 返回该节点 - 否则,如果节点是
TreeNode→ 调用getTreeNode在红黑树中查找 - 否则(链表)→ 遍历链表,逐个
equals比较
- 检查第一个节点:
- 未找到返回 null
三、扩容
触发条件:
==正常扩容:元素数量超过阈值(
size > threshold)====冲突过多时的“提前扩容”(而不是直接树化)==
- 新容量 = 旧容量 × 2(容量保持 2 的幂)
- 新阈值 = 新容量 × loadFactor
- 创建新数组
newTab - 迁移旧数组中的元素
线程安全问题:
==覆盖问题:线程1线程2都put一个hash值的,都先计算了,线程1先put直接就在数组[i],线程2再put还是在[i]位置(其实已经冲突了,该在链表)==
ConcurrentHashMap
1.7:数组+链表
写:
- 分段锁(Segment):继承
ReentrantLock,每个Segment相当于一个小型的HashMap(数组 + 链表)。 ConcurrentHashMap内部维护一个Segment数组,默认初始容量 16(并发度 16)。- 每个
Segment独立加锁,不同Segment之间可以并发写入
读:
- 完全无锁,因为
HashEntry的value和next都是volatile修饰,保证可见性。 - 先定位到
Segment,再遍历链表查找
扩容:
- 每个
Segment独立扩容,不影响其他段。 - 扩容时机:
Segment内部的count超过threshold(容量×负载因子)。 - 扩容时,段内锁会锁定,复制数组(2 倍),保持链表结构
1.8:数组+红黑树
- 取消分段锁,直接使用
Node<K,V>[] table数组(类似HashMap)。 - 锁粒度:每个数组桶的头节点(只锁住当前桶,而不是整个段)。
- 引入红黑树优化链表过长(>8)的情况。
写:
桶为空,不加锁,使用 CAS 原子地将新节点放入桶中
桶非空,使用
synchronized锁住该桶的头节点桶正在扩容(头节点为
ForwardingNode,hash = MOVED = -1)不加锁(因为锁住ForwardingNode没有意义),当前线程会协助迁移(调用helpTransfer()),然后重新尝试插入
读:
- 计算
hash,找到桶。 - 检查第一个节点是否匹配 → 返回。
- 若节点哈希为负数(表示正在扩容),调用特定查找方法。
- 否则遍历链表(
volatile保证可见性)。
扩容:
- 多线程协助扩容,每个线程负责一部分桶(从后往前分配)。
- 迁移过程中,旧数组的桶会被标记为
ForwardingNode(哈希值MOVED = -1),新 put 请求会帮助迁移。 - 迁移完成后,
table指向新数组
==ForwardingNode表示的是当前桶已经迁移完成,但整个数组是正在迁移的状态,所以get的时候就链接到新数组了,put的时候根据这个得知整个数组正在迁移,从而协助迁移==
问题
1. 为什么 JDK 1.8 要放弃分段锁?
- 分段锁内存开销大,且并发度受限于段的数量(默认为 16)。
- 现代并发场景更倾向于细粒度锁 + CAS,
synchronized经过优化后性能与ReentrantLock差距很小。 - 结合红黑树,查找和修改性能更好。
2. 为什么使用 synchronized 而不是 ReentrantLock?
synchronized在 JDK 1.6 后进行了大量优化(偏向锁、轻量级锁等),性能已经不差于ReentrantLock。- 代码更简洁,不需要显式解锁,降低了出错的概率。
LinkedHashMap
LinkedHashMap 是 HashMap 的一个子类,在 HashMap 的基础上维护了一个双向链表,用于记录元素的插入顺序或访问顺序
LinkedHashMap的每个节点(Entry)继承自HashMap.Node,增加了before和after指针。- 内部维护一个双向链表的头尾(
head和tail)。 - 在
put、get、remove等操作时,除了操作哈希表,还会同步更新双向链表以保持顺序。将访问的节点移动到链表尾部(表示最近使用)
==可以用作构建LRU缓存==
TreeMap
- 继承关系:
TreeMap<K,V>extendsAbstractMap<K,V>implementsNavigableMap<K,V> - 底层结构:红黑树(自平衡的二叉查找树)
- 核心特性:所有键值对按照键的自然顺序(
Comparable)或构造时指定的Comparator进行排序

Set
- HashSet
基本HashMap实现
先判断hashcode,相同再判断equals
- LinkedHashSet
满足FIFO场景,基于LinkedHashMap实现
- TreeSet
自定义排序场景【红黑树】
Queue
- Deque【接口】具体实现由:ArrayDeque和LinkedList
- PriorityQueue【二叉堆】
- BlockingQueue【接口】