
分布式MySQL
分区表为什么不够了?
- 仍在单机:所有分区仍然在同一个MySQL实例、同一块磁盘/磁盘阵列上。这意味着:
- IO瓶颈:所有分区的数据读写最终会争用同一套物理硬件(CPU、内存、磁盘IO、网络带宽)。当数据量和并发达到单机上限时,性能会达到天花板。
- 连接数瓶颈:所有连接都连接到同一个MySQL实例,受
max_connections限制。 - 可用性风险:单点故障。该实例宕机,整个表(所有分区)都不可用。
结论:分区表是单机数据库性能优化的高级手段,但无法突破单机硬件资源的根本限制。
垂直分库分表
垂直分库
例如微服务按业务功能将表拆分到不同数据库,例如:
- 订单库:
order,order_item - 用户库:
user,user_profile - 商品库:
product,category
垂直分表
将一张宽表按列拆分为多张表:
- 主表:存放频繁访问的字段(
user_id,nickname,age) - 扩展表:存放冷门或大字段(
bio,avatar,settings)
优点:减少 IO 阻塞,提高缓存命中率。
水平分库分表
==这是最常用的分库分表手段==
常见分片算法

一致性哈希
就像一个有刻度的圆盘,数据和服务器都放在上面。数据顺时针找最近的服务器。增加或减少服务器时,只影响相邻一小段的数据,而不是全部重来。** 它是分布式系统(如缓存、数据库分片)==平滑迁移扩容==的基石
路由
(以ShardingSphere-JDBC为例)
假设我们配置了:
- 分库键:
user_id,分库算法:user_id % 4→ 4个库(ds0~`ds3`) - 分表键:
user_id,分表算法:user_id % 2→ 每库2张表(t_user_0、t_user_1) - 实际物理表:
ds0.t_user_0、ds0.t_user_1、ds1.t_user_0、ds1.t_user_1……
等值路由:
1 | SELECT * FROM t_user WHERE user_id = 123; |
路由步骤:
- 解析SQL,提取
user_id = 123。 - 分库计算:
123 % 4 = 3→ 目标库ds3。 - 分表计算:
123 % 2 = 1→ 目标表t_user_1。 - 最终路由到:
ds3.t_user_1。
范围路由:
1 | SELECT * FROM t_user WHERE user_id BETWEEN 100 AND 200; |
- 分片算法无法精确计算到单一值,中间件会计算所有可能的分片:
- 对于
user_id在 100~200 范围内,%4的结果可能是 0,1,2,3 全有。 - 因此路由到所有库的所有表(广播),然后在应用层合并结果。
- 对于
不带分片键:
1 | SELECT * FROM t_user WHERE name = '张三'; |
- 没有
user_id,无法确定分片。 - 默认行为:广播到所有分片(
ds0.t_user_0~`ds3.t_user_1`),然后合并结果。 - 必须避免广播,可以建==索引表==(
name→ `user_id),或者基因法具体怎么实现:- 核心思想:将分片键信息“编码”进业务主键。
- 定长:假设分16张表,取
buyer_id后4位bit 作为“基因”。 - 移位:将“基因”嵌入
order_id(order_id << 4 + 基因)。 - 解析:查询
order_id时,解析出ID末尾的“基因”,直接路由到目标分片。
- 定长:假设分16张表,取
- 核心思想:将分片键信息“编码”进业务主键。
问题
🤔 “非分片键如何查询?比如按买家ID分片,卖家怎么查?”
- 基因法(最优):将
buyer_id的基因(如后几位)融入order_id,解析ID即可定位。 - 索引表:建立映射关系表,二次查询后获取数据。
🤔 “跨节点JOIN查询怎么解决?”
- 字段冗余:在表中直接存储常关联的字段,避免查询关联表。
- 全局表:配置表等小表在每个库都存一份,实现本地JOIN。
🤔 “分库分表后,如何进行分页查询(尤其是深度分页)?”
- 不允许跨页跳转:前端每次传入上一页末尾游标,规避
OFFSET。
🤔 “分库分表后,如何保证全局主键ID的唯一性?”
- 数据库分段号:批量获取ID段,性能好。
- 雪花算法(Snowflake):64位长整型,趋势递增、不依赖数据库,是业界最主流方案。
🤔 “分库后,怎么保证数据一致性?”
- 最佳实践:规避 → 最佳实践:规避 → 最佳实践:规避。从设计上避免跨分片事务(如用
order_id同时分库分表)。 - 柔性事务(TCC/Saga):高性能场景下的最终一致性方案。
分布式ID
1. UUID (Universally Unique Identifier)
- 实现方式:JDK 内置
UUID.randomUUID().toString()生成类似550e8400-e29b-41d4-a716-446655440000的36位字符串。 - 作为数据库主键的致命缺陷:在 MySQL 中,其无序性会导致 B+ 树索引频繁的页分裂(Page Split),严重影响写入和查询性能。
2. 数据库自增
- 多实例部署:通过设置
auto_increment_increment(步长)和auto_increment_offset(起始值)规避冲突。例如两台机器,步长设为 2,一台从 1 开始,另一台从 2 开始。 - 致命缺陷:扩展性极差!假设要从2台扩容到3台,必须重新规划所有实例的步长和偏移量,甚至需要数据迁移,操作复杂且风险高。
3. 雪花算法
ID结构:64位整数 [1位符号位 | 41位时间戳(毫秒级,可用69年)| 10位机器ID | 12位序列号(单节点每毫秒最多4096个ID)]。
时钟回拨问题及解决方案:雪花算法强依赖系统时间,一旦发生时钟回拨(如NTP同步),可能生成重复ID。
NTP(网络时间协议)同步:为了保持服务器时间准确,系统会定期与NTP服务器同步。如果本地时间过快,NTP服务会将时间小幅度回调(通常是毫秒或微秒级)进行校准。
应对方案如下:
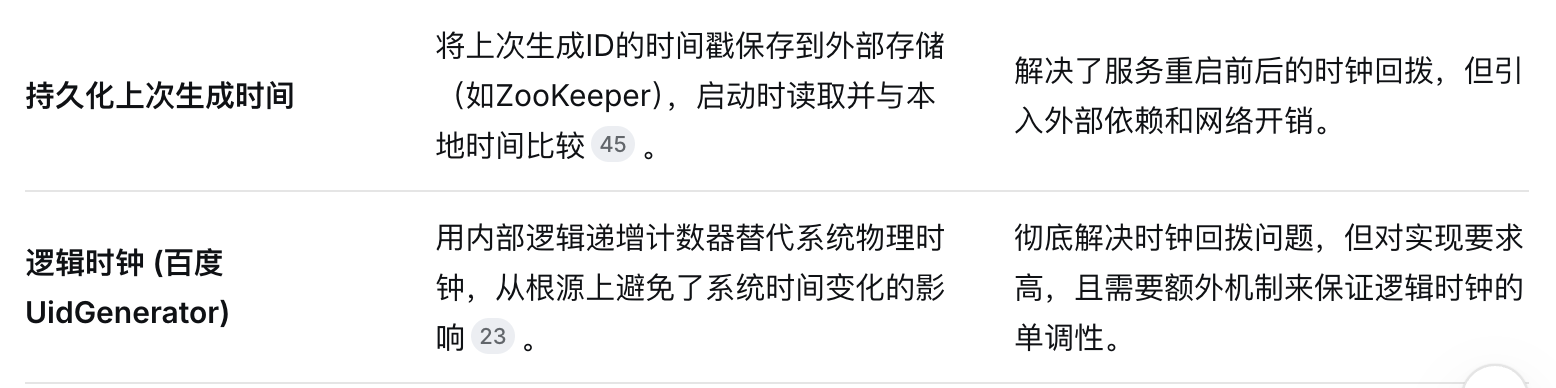
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 夏天的风吹向哪里!


